Stateless Software Engineering
How to future-proof team context against human turnover and AI amnesia.

The most dangerous phrase in software engineering is "ask Bob, he knows." The second most dangerous is "the agent will remember." Both are wrong for the same reason.
It’s Tuesday afternoon. A critical production issue lands in your lap — something in the authentication pipeline is misbehaving, and the one engineer who built it three years ago hasn’t replied to your messages in two hours. You pull up the Confluence page. Last updated: 2021. The architecture diagram references a service that was decommissioned eighteen months ago. You ask around. “Oh, Bob knows that system inside out.” Bob is on holiday. Bob is always on holiday when you need him.
Every software team has a Bob. Bob is great. Bob is also a single point of failure. And the uncomfortable truth is that Bob won’t be at the company forever.
This is the problem of knowledge state — the unwritten rationale, the oral tradition, the architectural understanding that lives exclusively in people’s memories. Software teams, like software systems, carry state. And when the server goes down — when someone leaves, gets promoted, or simply isn’t available — that state is lost. The average software engineer changes jobs every 2 to 3 years. Remote and async work has made the “tap on the shoulder” obsolete. A team of 5 can get by on conversation; a team of 50 cannot.
Now add a new dimension: AI coding agents. They’re joining our teams in ever-increasing numbers — drafting pull requests, reviewing code, debugging issues. And they have the exact same problem Bob has, except worse. Large language models are stateless by design. Every API call starts from zero. They don’t remember what they did five minutes ago, let alone yesterday. Give them a context window big enough to hold an entire conversation, and they still forget the moment the session ends.
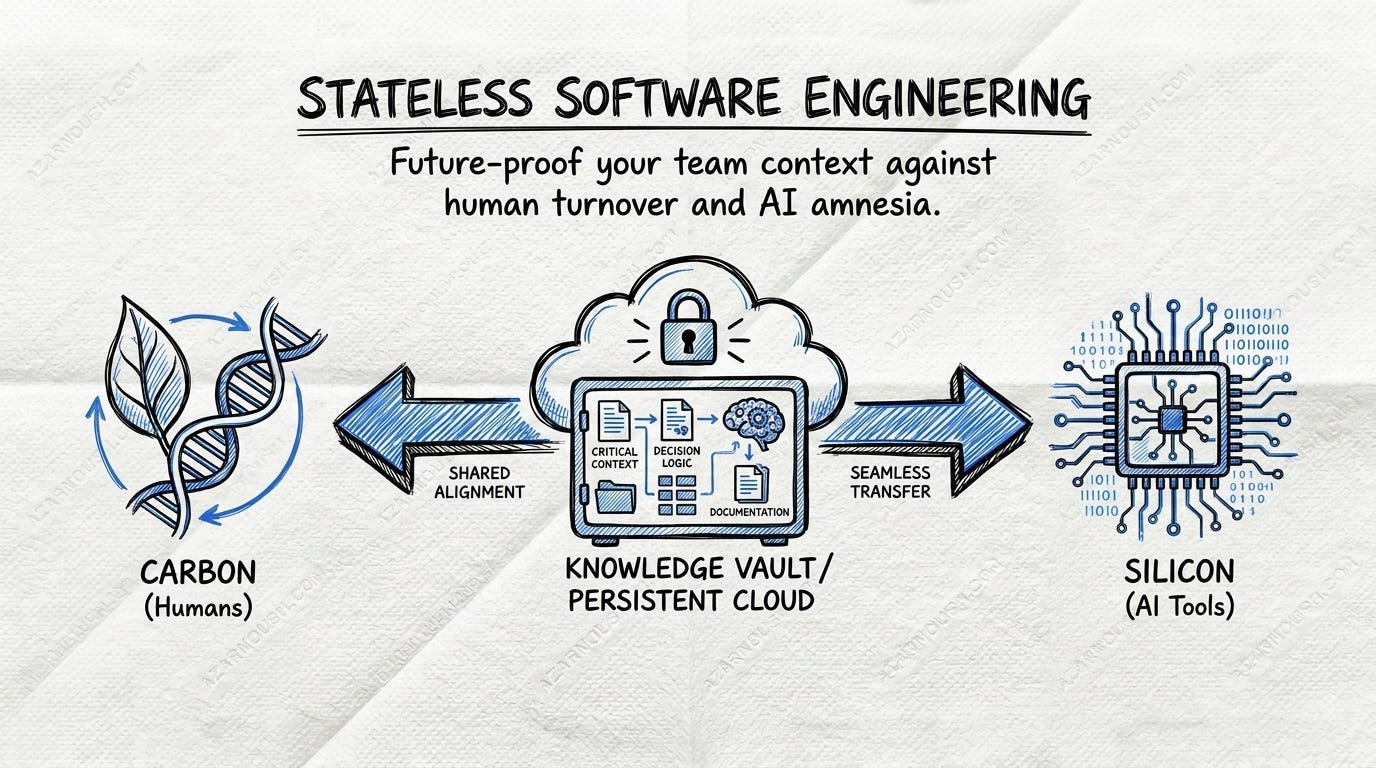
The question this article asks: what would software engineering look like if we designed for statelessness — for both humans and agents? Not stateless in the compute sense — stateless in the knowledge sense. What if every team member, carbon (human) or silicon (AI), could understand why a decision was made without needing to find the one entity that carries that context?
What Stateless Software Engineering Is (and Isn’t)
In distributed systems, a stateless server stores no session data locally. Any instance can handle any request because state lives in an external, replicated store. Apply this to engineering teams, and the analogy holds remarkably well: knowledge should live in durable, shared, version-controlled artefacts — not in individual minds.

Stateless software engineering is the set of practices that externalise knowledge from individuals into the team’s collective memory. The core principle is almost provocative in its simplicity: if it’s only in someone’s head, it doesn’t exist. It doesn’t exist for the new hire. It doesn’t exist for the remote teammate in a different timezone. It doesn’t exist for the AI agent that’s trying to help you. And it certainly doesn’t exist after that person walks out the door.
This is not about eliminating conversation, collaboration, or expertise. It’s not about turning engineers into documentation clerks. And it’s absolutely not about documenting everything — it’s about documenting the right things: decisions, rationale, and context, at the moment they’re made. Write when a new team member — or a new agent — would ask “why.”
It’s also not theoretical. Companies at every scale — from AWS to SPS Commerce to manufacturing plants — have built cultures around these practices. Not because they enjoy paperwork, but because the cost of not doing it kept showing up on their balance sheet.
Here are the five practices that turn knowledge from something carried in someone’s head into something the whole team — humans and agents alike — can rely on.
Five Practices That Make Knowledge Durable
1. Architecture Decision Records (ADRs)
An ADR is a lightweight markdown document — often just a few hundred words — that captures an architectural decision, the context that led to it, the alternatives considered, and the consequences. It lives in Git, in the same repository as the code it describes. It gets reviewed in pull requests, just like code.
The format is so simple it’s almost boring. That’s the point. AWS best practices after 200 ADRs across more than 10 projects share significant insights. Their readout meetings follow a structured ritual: 10 to 15 minutes of silent reading, then written comments, then discussion. Decisions that once required weeks of cross-team coordination now resolve in 1 to 3 sessions. Before ADRs, 20 to 30 percent of development time went into alignment overhead. After, teams could operate with more autonomy because the ADRs provided the shared context.
The real magic of ADRs is that they answer the single most common question every new team member asks: “Why did we build it this way?” They turn decisions into immutable history — the rationale survives the people who made it. And here’s the thing about AI agents: an ADR is a perfect data source for them. It’s structured, it’s version-controlled, and it captures exactly the context an agent needs to understand architectural constraints without hallucinating.
“The impact of adopting this process is disproportionately bigger than the simplicity suggests.” — AWS ProServe team
2. Design Docs Before Code
At Google, engineers write design documents for essentially all non-trivial work. These aren’t implementation manuals — they’re narrative documents written before coding that capture strategy, key design decisions, and trade-offs. The most important section, according to Google’s Malte Ubl, is “Alternatives Considered”: it captures the trade-off space, not just the chosen path.
The insight is that writing is thinking. The act of structuring a design doc forces clarity in a way that whiteboarding doesn’t. It separates deciding what to build from building it. And because the docs stay alive and get updated during maintenance, they serve as long-term organisational memory. An engineer years later — or an agent prompted with the doc — can understand why a system works the way it does.
Amazon takes this even further. Jeff Bezos banned PowerPoint in 2004. Every significant proposal is a six-page, narratively-structured memo. Meetings start with 20 to 30 minutes of silent reading. Documents are author-anonymous, so ideas are evaluated on merit, not credentials. Bezos called it “the smartest thing we ever did at Amazon.”
3. Documentation-as-Code
The answer to “where is the documentation?” should always be the same: “in the repo.” Documentation-as-code means treating docs with the same rigour as production code — version-controlled in Git, written in plain text, built with static site generators, reviewed via pull requests, tested in CI.
SPS Commerce, a retail network serving over 50,000 customers, faced a familiar mess: documentation scattered across Slack, Confluence, GitHub READMEs, SharePoint, and oral tradition. Engineers were “trying to build first rather than find first” — duplicating work because answers weren’t discoverable. They centralised their internal docs with GitHub Pages, pulling content nightly from each team’s repositories. The result: “Questions that previously took hours — or required tapping multiple teammates — could now be answered in minutes.”
The pattern that made it work: centralised infrastructure, decentralised ownership. Every team owns their content; a central platform makes it discoverable. Engineers contribute because the toolchain is the same one they already use for code. And critically for the agent era: docs-as-code produces machine-readable, version-controlled text that agents can ingest directly.
4. Automated Knowledge Bases
Knowledge bases need structure and ownership. Without them, they become “the shared drive” — a dumping ground nobody trusts. The most effective ones proactively extract, structure, and maintain institutional knowledge.
The manufacturing sector offers a stark preview of what happens without this. Envases, a packaging company, faced a wave of retiring process supervisors with decades of undocumented knowledge. They filmed experts performing critical procedures and used AI to generate visual guides, capturing irreplaceable expertise in a reusable format. Training time dropped from 12 weeks to 3. The broader context is sobering: 2.4 million unfilled manufacturing jobs are projected by 2028. When knowledge isn’t externalised, retirements become knowledge-loss events.
5. Living Documentation
The most trustworthy documentation is the kind that can’t be out of date because it’s verified on every build. Cyrille Martraire‘s Living Documentation (O’Reilly) champions this approach: documentation that evolves continuously with the codebase. Executable specifications — plain-language scenarios (such as Cucumber tests) that describe expected behaviour — serve as documentation that CI enforces. When the behaviour changes and the test isn’t updated, the build fails. The documentation, in effect, can’t lie.
This is the most agent-friendly form of documentation because it’s machine-verifiable. An agent can’t hallucinate its way past a failing test.
The AI Agent Dimension: Stateless by Nature
So far we’ve talked about humans. But the arrival of AI coding agents — Claude Code, Copilot, Cursor, specialised in-house agents — changes the equation. These agents are joining our teams, and they have a fascinating property: they are stateless by default.
“By default, LLMs are stateless. When you ask an LLM a question, it processes that query independently without remembering your last conversation.”
Every API call starts from zero. Every session is an amnesiac. Every agent wakes up with no memory of what it did yesterday. This is not a bug — it’s the fundamental architecture of transformer-based models. As Letta puts it, “Large language models possess vast knowledge, but they’re trapped in an eternal present moment.”
Now, you might think the solution is obvious: give them memory. Vector databases. RAG. Context windows. And the industry is certainly trying. But here’s the uncomfortable truth that’s emerging from both research and production experience: embedding memory into agents creates as many problems as it solves.
Why Agent Memory Is Fundamentally Different from Human Memory
It’s tempting to think of agent memory as a direct parallel to human memory. It’s not. The differences are profound, and they matter for how we design systems.
Humans forget naturally. Agents must be taught to forget. Human memory is lossy by design. We don’t remember every meal we’ve ever eaten, every line of code we’ve ever read, every conversation we’ve ever had. This is a feature, not a bug. Our brains prune aggressively, retaining what’s important and discarding the rest. AI agents, by contrast, either remember everything (in a vector database) or nothing (stateless). They have no native sense of what’s worth keeping and what’s noise. As the MemoryAgentBench paper — the first benchmark to treat forgetting as a core competency — puts it:
“We identify four core competencies essential for memory agents: accurate retrieval, test-time learning, long-range understanding, and selective forgetting.”
— Hu, Wang & McAuley, ICLR 2026
Selective forgetting is not a failure mode. It’s a capability. And current agents don’t have it.
Humans know when they’re uncertain. Agents don’t. When Bob says “I think we built it this way because…”, you know to verify. When an agent retrieves a memory from a vector store, it presents it with equal confidence regardless of relevance. The memory might be from a completely different project, a different year, or a different context — and the agent will treat it as ground truth. Nick Lawson, writing from hard-won production experience, calls this “self-reinforcing errors — a bad memory becomes ground truth, distorting all subsequent reasoning.”
Human memory degrades gracefully. Agent memory fails catastrophically. When Bob forgets something, he usually knows he’s forgotten it. He says “I’d need to look that up.” An agent with a polluted memory doesn’t know it’s polluted. It just produces wrong answers with high confidence. The degradation is silent.
Humans update their mental models. Agents accumulate staleness. The world changes — APIs deprecate, services are renamed, teams reorganise. Humans (mostly) update their understanding. Agent memory, stored in a vector database or summarised into a context window, doesn’t. As Lawson notes: “Staleness is probably most common. The outside world changes, but your system memory doesn’t. Long-lived agents will act on data from 2024 even in 2026.”
The Forgetting Problem: Why Remembering Everything Is the Real Danger
The industry’s first instinct with agent memory was “remember everything.” Log every interaction. Embed every decision. Store every preference. The result, across dozens of production systems, has been consistent: the agent gets worse, not better.
There are several reasons for this:
Context pollution. As Letta’s research documents, “RAG-based memory retrieval pollutes context with irrelevant data, degrading performance — especially for reasoning models.” When you retrieve memories by semantic similarity, you get things that sound relevant but aren’t causally connected. The agent’s context fills with plausible-sounding noise.
Context rot. Researchers have identified a phenomenon where model performance degrades well before the advertised context window limit. A 200,000-token model might become unreliable at 130,000 tokens. The Oracle team notes that context windows “degrade before they fill up.” Every token is treated equally — your critical architecture decision gets the same weight as a three-week-old throwaway comment about lunch.
Summarisation drift. When agents compress long conversations into summaries, detail is lost. Then the summary is summarised. Each pass strips away nuance until the memory no longer matches reality. “Repeated compression strips away details until memory no longer matches reality,” Lawson writes. He reports that even in tools like Claude Code, restarting a fresh thread often works better than compressing an over-long conversation.
Catastrophic interference. The arXiv paper on governing evolving memory identifies “semantic drift” as a primary failure mode. When an agent continuously updates its own memory, ungoverned, it “acts as both the sole generator and validator of its evolving knowledge base” — a recipe for drift, contradiction, and eventual nonsense. The paper’s central finding: stability and adaptability are in tension. The more adaptive a memory system, the more vulnerable it is to corruption.
“Current memory systems predominantly prioritise adaptability... over stability and safety. This unconstrained autonomy is the primary catalyst for semantic drift, catastrophic forgetting, and susceptibility to adversarial memory poisoning.”
The parallel to human teams is exact. A team where everyone keeps knowledge in their heads is highly adaptive — decisions can be revisited, context shifts instantly. But it’s also fragile — one departure, one holiday, one busy week, and the knowledge is gone. The fix, for both humans and agents, is the same: externalise knowledge into durable, governed, version-controlled artefacts that don’t depend on any single entity’s memory.
Memory as External Infrastructure
If embedding memory into agents creates chaos, what’s the alternative? The emerging consensus — from Redis to Salesforce to Weaviate to the academic community — is that memory should be external infrastructure, not embedded state.
“Agent memory is a system-design problem, not a prompt-engineering problem. Avoid storing state solely in prompts, ad-hoc files, or unencrypted client storage.”
Think of it this way: we don’t build databases into our application servers. We run them as separate services with their own guarantees, their own backups, their own access controls. Agent memory needs the same treatment. An agent should retrieve context from an external, governed store — the same store that humans use. The ADRs, the design docs, the knowledge base, the living documentation. Not a private vector database of half-remembered conversations.
“Developers will call memory.write() as easily as they now call db.save(). Expect specialised providers of middleware memory to evolve into middleware for every agent platform.”
Salesforce’s Agentforce team, building agentic memory at the scale of millions of enterprise users, arrived at the same conclusion: “Decoupling data sources makes the derivation pipeline a flexible, extensible enterprise memory platform. Memories are derived from diverse sources, not just conversations, and stored in a standard memory object.” The agent doesn’t own its memory. The platform does.
This is the core insight of stateless software engineering applied to agents: the knowledge lives in the repo, not in the agent. The agent is a stateless processor that reads context from durable artefacts, acts on it, and writes results back. Just like a stateless web server reads from a database.
The practical implication is clear: invest in your documentation, your ADRs, your design docs, your living tests. They are not just for your human teammates. They are the memory infrastructure that your agents will depend on. A well-documented codebase is not just maintainable — it’s agent-readable. A poorly documented codebase is not just frustrating for new hires — it’s agent-hostile.
“The gap between ‘has memory’ and ‘does not have memory’ is often larger than the gap between different LLM backbones.”
The quality of your externalised knowledge determines the quality of your agents’ output. Not the model. Not the prompt. The memory.
Why This Matters: The Benefits
Faster onboarding — for humans and agents. New hires bootstrap context by reading past design docs and ADRs instead of pinging veterans. Questions that took hours dropps to minutes. An agent pointed at the same docs can contribute from its first prompt.
Knowledge retention across entities. When endjin, a UK consultancy, needs to understand a decision from three years ago, they roll back to the relevant Git commit. The ADRs are there — the exact architecture documentation for that point in time. Neither the original engineer nor the original agent needs to be available.
Team resilience. Every ADR, every design doc, every living test raises the team’s bus factor. No single person — and no single agent — becomes the sole carrier of critical context.
Agent reliability. An agent that reads from version-controlled, human-reviewed documentation produces more reliable output than an agent relying on its own memory. The documentation is the source of truth; the agent is just a processor.
Better decisions — by humans and agents. The process of writing an ADR or a design doc improves the quality of the decision itself. Considering alternatives forces rigour. And when an agent can read those alternatives, it understands not just what was decided but why — which is exactly the context it needs to make better suggestions.
“As software engineers our job is not to produce code per se, but rather to solve problems. Unstructured text, like in the form of a design doc, may be the better tool for solving problems early in a project lifecycle.” — Malte Ubl, Google
The Honest Challenges
This all sounds good. It also sounds like work. Let’s address the sceptic directly.
“Writing takes time, and we’re behind on delivery.”
The cost of not writing is higher — it’s just deferred and invisible. AWS ProServe’s teams spent 20 to 30 percent of their time on coordination before ADRs. That’s not free. Start with one ADR for the next significant decision. The ROI becomes visible fast.
“Docs rot. Stale docs are worse than no docs.”
This is true. It’s also the strongest argument for docs-as-code and living documentation: when doc updates are part of the definition of done, and when living documentation breaks on CI, rot slows dramatically.
“I’m a builder, not a writer.”
Writing is building — it’s building shared understanding. A 300-word markdown ADR doesn’t feel like bureaucracy. It feels like leaving a note for your future self. And increasingly, it’s leaving a note for your future agents.
“The agents will figure it out.”
They won’t. Agents are stateless. They have no native memory. They hallucinate when context is missing. The quality of their output is directly proportional to the quality of the context you give them. Garbage documentation in, garbage code out.
“We don’t need formal records for everything.”
Correct. Google’s guidance is useful here: if the doc is essentially an implementation manual without discussing trade-offs, alternatives, or decision rationale, skip it. Write when a new team member — or agent — would ask “why.”
“Our team is stable. Nobody’s leaving.”
Bob might not leave, but he might go on holiday. He might get pulled onto a different project. Statistics say he’ll probably change jobs within 2 to 3 years. And your agents — they “leave” at the end of every session, their context windows evaporating into nothing. Don’t frame this as insurance against departures — frame it as a productivity investment for everyone still there.
Where to Start
This doesn’t need to be a grand initiative. It starts small and compounds.
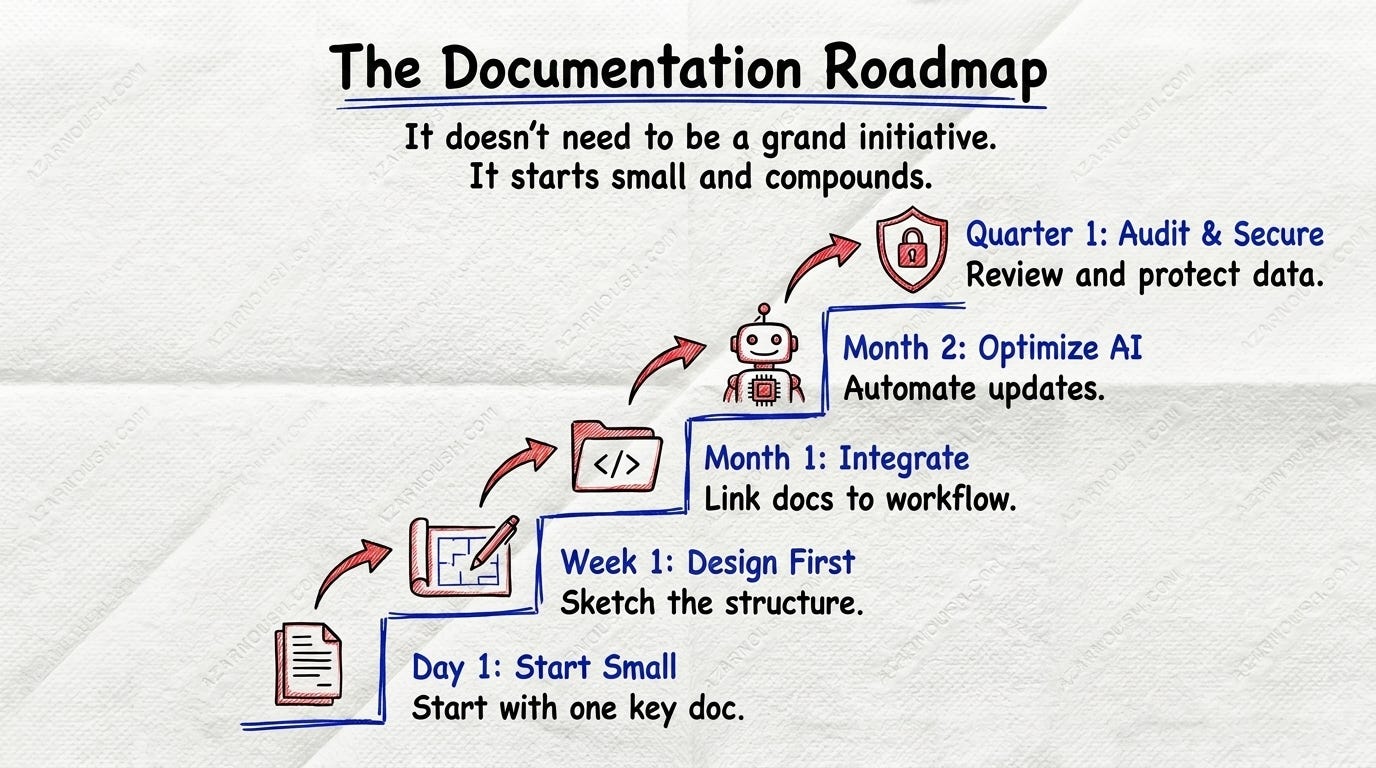
Day one: Write your first ADR for the next architectural decision. A few hundred words of markdown. Commit it.
Week one: Adopt the “design doc before code” habit for one non-trivial feature. Include an alternatives-considered section.
Month one: Move documentation into the repo alongside the code. Start treating doc updates as part of the definition of done.
Month two: When you onboard an AI coding agent, point it at your ADRs and design docs first. Notice how much better its suggestions become.
Quarter one: Audit your team’s knowledge. What lives only in people’s heads? What lives only in agent context windows that vanish at session end? Capture the highest-risk items first. Make them durable.
Each artefact makes the next one easier. Each ADR becomes a reference for future decisions. Each design doc sets a precedent for depth and quality. The ROI compounds — every new hire, every departure, every agent session, every decision benefits from the accumulated knowledge base.
The New Paradigm
For decades, we built software in a stateful way. Knowledge lived in engineers’ memories. That’s why people in engineering teams were — and are — so important. Companies tried to retain them. Big organisations spent fortunes extracting that knowledge into documentation, often wastefully, often poorly. It’s one of the main reasons large projects move slowly.
We are now delegating more and more work to AI agents — small, crafted tools that handle different parts of the development process. These agents are stateless by nature. Every session starts fresh. Every context window eventually expires. This is not a limitation to be overcome with cleverer memory systems bolted onto the agent. It’s a feature — if we build the external infrastructure they need.
The vision of stateless software engineering is this: knowledge lives in the repo. In ADRs. In design docs. In living tests. In version-controlled, human-reviewed, machine-readable artefacts. Humans read them. Agents read them. Neither depends on the other’s memory. When Bob leaves, the knowledge stays. When the agent’s session ends, the knowledge stays. The processor is disposable; the memory is durable.
The most dangerous phrase in software engineering is “ask Bob, he knows.” The second most dangerous is “the agent will remember.” The most liberating is still — and always will be — “it’s in the repo.”
Further Reading
Master Architecture Decision Records (ADRs): Best Practices — AWS Architecture Blog (March 2025)
Design Docs at Google — Malte Ubl
The Amazon Writing Culture — How Bezos banned PowerPoint and built a writing-first culture
Internal Documentation at Scale: SPS Commerce Case Study — Fern Blog (August 2025)
Architecture Decision Records at endjin — James Broome
Living Documentation: Continuous Knowledge Sharing by Design — Cyrille Martraire (O’Reilly)
Stateful Agents: The Missing Link in LLM Intelligence — Letta (Feb 2025)
AI Agent Memory: Building Stateful AI Systems — Redis Blog (Feb 2026)
A Practical Guide to Memory for Autonomous LLM Agents — Nick Lawson (Apr 2026)
Memory for AI Agents: A New Paradigm of Context Engineering — The New Stack (Jan 2026)
MemoryAgentBench: Evaluating Memory in LLM Agents (ICLR 2026) — Hu, Wang & McAuley
Governing Evolving Memory in LLM Agents (arXiv) — Lam et al. (Mar 2026)
Agent Memory: Why Your AI Has Amnesia and How to Fix It — Oracle Blog (Feb 2026)
Thanks to the teams at AWS ProServe, endjin, SPS Commerce, Google, Letta, Redis, and the researchers behind MemoryAgentBench and SSGM whose public writing made this article possible. If you’ve built a stateless engineering culture — for humans, agents, or both — I’d love to hear about it.