Why Gemma 4 changes everything
From locked API to open infrastructure


Google released Gemma 4 on a Tuesday, and within hours, the open-source community had already pulled it, quantised it, fine-tuned it, and deployed it on hardware that fits in a jacket pocket. That sentence would have been absurd two years ago. The best AI models, the ones that could reason, code, see, and act, lived behind proprietary APIs. You paid per token. You accepted rate limits. You agreed to terms of service that could shift overnight. Your data transited someone else’s servers. Your product depended on infrastructure you neither controlled nor understood.
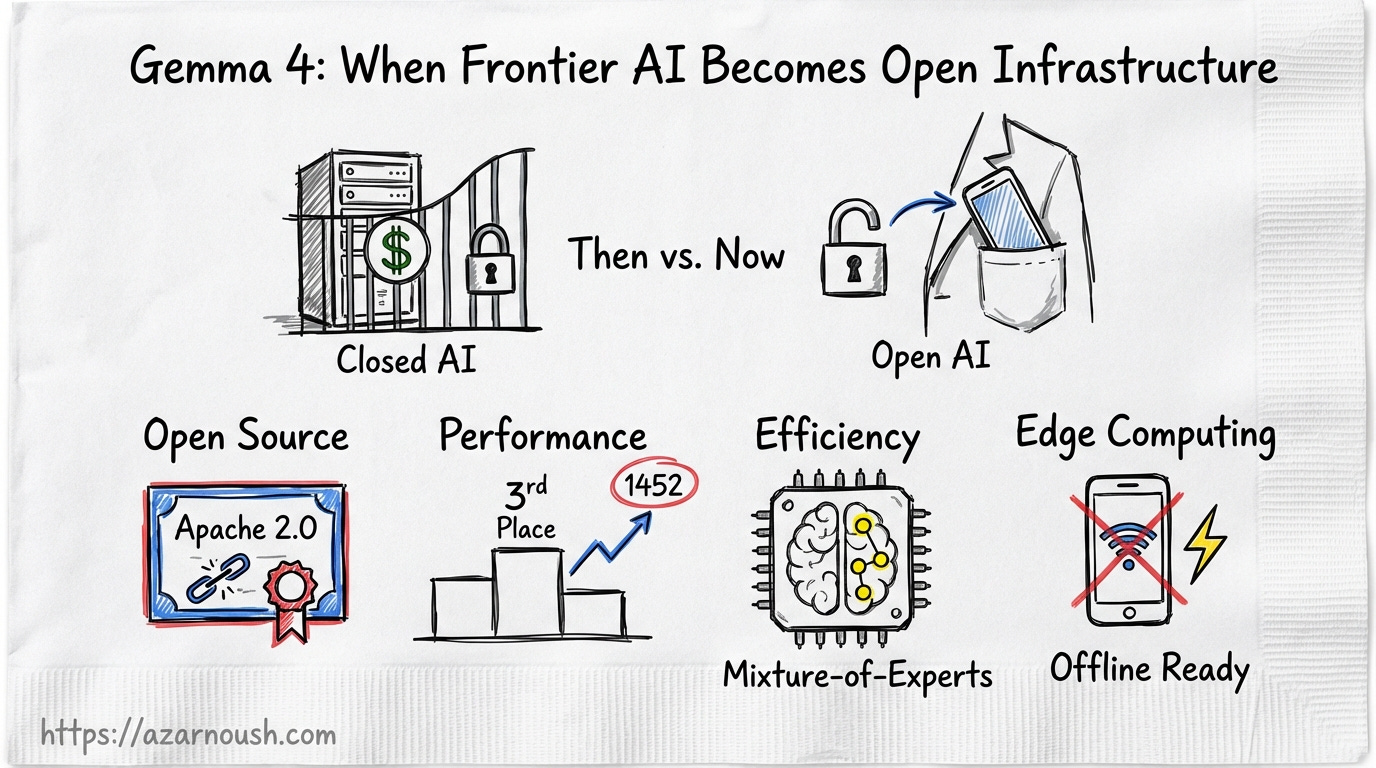
Gemma 4 under Apache 2.0 dismantles that arrangement. This is not a toy model dressed up in open-source clothing. The 31B dense variant ranks third among all open models globally on the Arena AI text leaderboard with a score of 1452. The 26B Mixture-of-Experts variant activates only 3.8 billion parameters at inference while delivering quality that competes with models five times its size. The edge variants, E2B and E4B, run entirely on a phone, offline, no internet required. And every single weight ships under a licence that lets you do whatever you want with them, commercially, with no restrictions.
This is the story of what happens when frontier-class AI becomes infrastructure instead of a service.
What it means for general consumers
Your phone just got a PhD
Short-term. Gemma 4’s E2B and E4B models execute entirely on-device. No cloud round-trip. No latency spike when the train enters a tunnel. No data packet leaving your handset for processing on a server farm in Virginia. Smart replies that understand context. Live translation that works in airplane mode. Voice assistants that respond in milliseconds because they are not waiting on a network request. Photo understanding that runs locally and classifies what your camera sees without uploading a single frame.
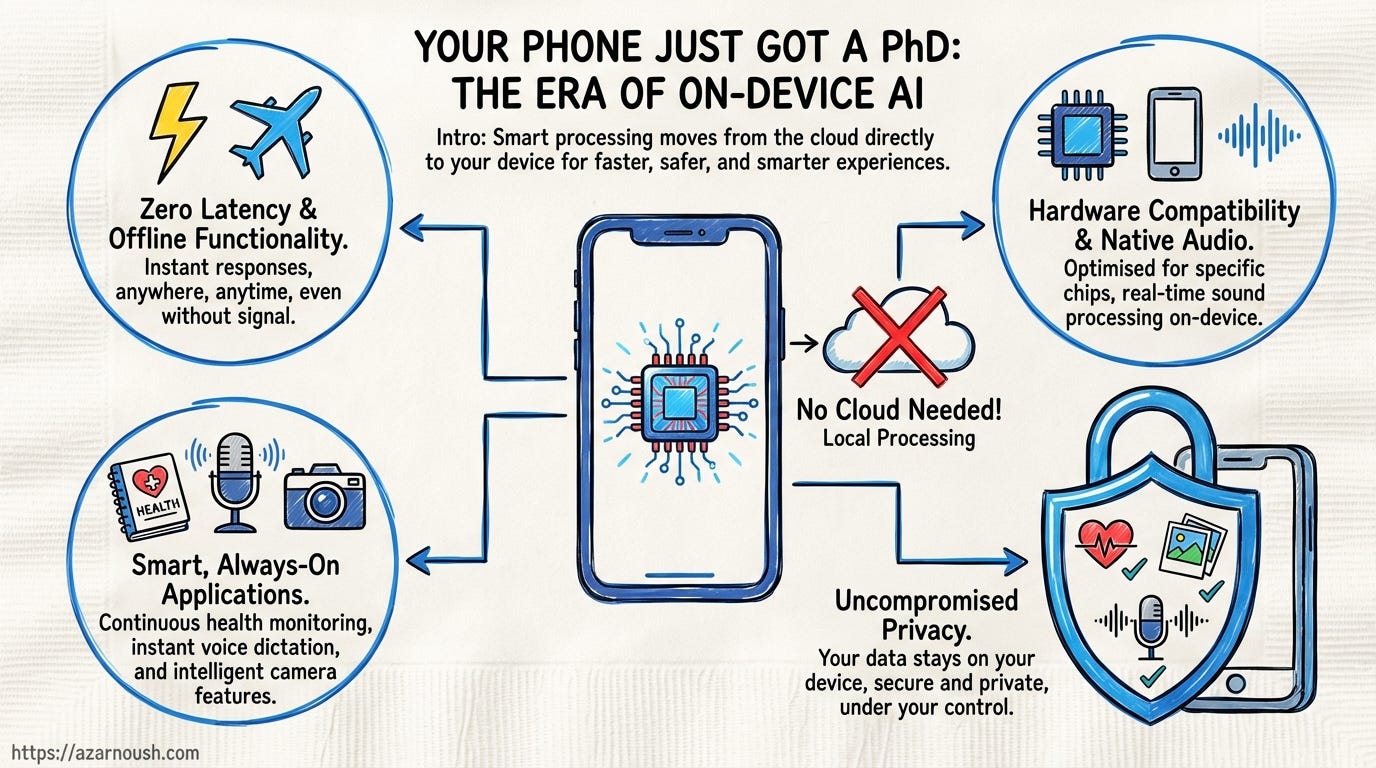
This is not speculative. Google co-designed these models with Qualcomm and MediaTek for on-device deployment. They run on Android handsets, iOS devices, Raspberry Pis, and NVIDIA Jetson Orin Nano boards. The E2B variant is an effective 2-billion-parameter model. The E4B doubles that. Both include native audio input, not just text processing, but actual speech understanding baked into the model architecture.
Long-term. The implications compound. As app developers integrate these models, a new category of always-on AI features emerges. Health apps that parse your voice notes and detect patterns in how you describe symptoms. Camera applications that genuinely understand scene composition, not through a cloud API but through a local model running at 30 frames per second. Journaling tools that offer contextual suggestions without ever reading your entries over a network connection.
The privacy angle is the clincher. For the first time, consumers can get AI features that rival cloud-dependent equivalents without the fundamental trade-off of sending personal data to a third party. Your health data stays on your phone. Your photos stay on your phone. Your voice recordings stay on your phone. The AI works anyway. That is not an incremental improvement. That is a categorical shift in what is possible at the intersection of AI and consumer privacy.
What it means for developers
A frontier model you can actually run locally
Short-term. Pull Gemma 4 via Ollama. Run it on your laptop GPU. You now have a coding assistant, a reasoning engine, and a multimodal model available at the command line, with no API key, no billing dashboard, and no usage cap. The 26B MoE variant is the one to watch: it delivers quality close to the 31B dense model while activating only 3.8 billion parameters per forward pass. That means frontier-class inference on consumer hardware, whether a MacBook Pro with sufficient unified memory, a desktop with a mid-range NVIDIA card, or even a well-specced cloud VM at a fraction of what you would pay for equivalent API usage.
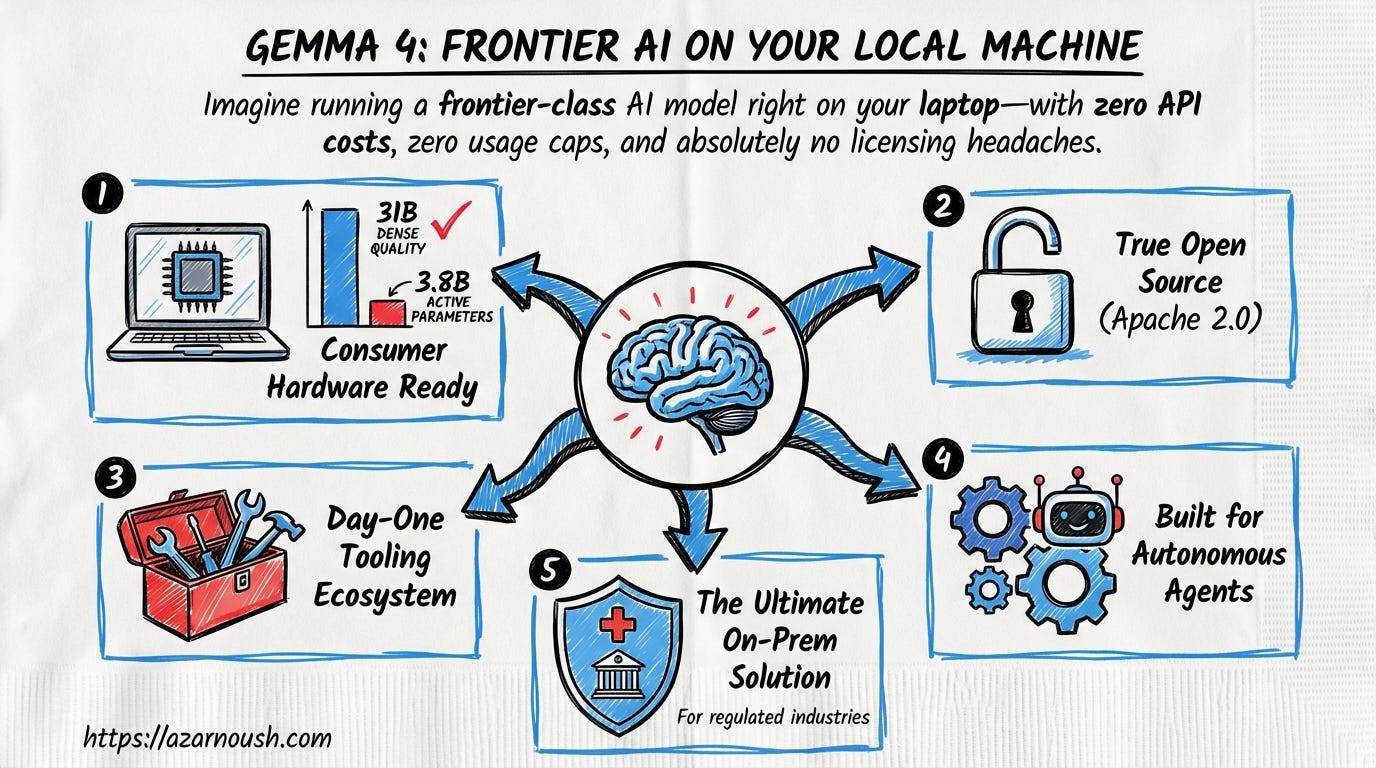
Apache 2.0 eliminates the licence headaches that plagued previous open-weight releases. No usage caps. No commercial restrictions. No ambiguity about whether your deployment violates terms. You download the weights, you run them, you build on top of them. The licence is one paragraph and it says yes.
The tooling ecosystem arrived fully formed on day one. Hugging Face transformers, llama.cpp, MLX for Apple Silicon, Transformers.js for browser-based inference, vLLM for high-throughput serving, Unsloth for fast fine-tuning, all supported at launch. Hugging Face’s own blog noted something remarkable: they struggled to find good fine-tuning examples because the models were so capable out of the box. When the community’s go-to platform for model experimentation says the base model is already too good to easily demonstrate improvement, that tells you something about where the quality bar has landed.
Long-term. The native function calling, structured JSON output, and configurable thinking mode make Gemma 4 a serious foundation for autonomous agents that run entirely on-premises. This is the architecture shift that matters most for the developer ecosystem. You are not wrapping a chat API in agent scaffolding and hoping the remote model follows your instructions. You are running a model designed from the ground up with agentic workflows in mind, one that can call tools, format structured outputs, and switch between fast and deep reasoning modes based on the task at hand.
For teams operating under constraints, healthcare startups bound by HIPAA, financial services firms working through regulatory requirements, government contractors with data residency mandates, this is the model family to build on. Not because it is the cheapest option, but because it is the first option where the economics, the licensing, and the performance all line up to make on-prem deployment the rational default rather than the expensive exception.
What it means for researchers
Open weights, frontier architecture, no strings attached
Short-term. Apache 2.0 licensing removes the legal ambiguity that slowed adoption of previous Gemma releases. The original Gemma custom licence was permissive in practice but contained usage restrictions that created friction in institutional review processes. Research ethics boards and legal departments at universities do not move fast. When a licence requires careful reading, the default answer is often “not yet.” Apache 2.0 is a known quantity. It is OSI-approved. It has been vetted by every major open-source foundation. The answer is yes, immediately.
Researchers now have access to the same architectural innovations that power Google’s proprietary Gemini 3. Mixture-of-Experts routing. Per-Layer Embeddings. Hybrid attention mechanisms. Full weight transparency, not a distilled approximation. The 256K context window opens up research directions that were previously locked behind proprietary APIs or required cobbling together context extension hacks on smaller models. Support for over 140 languages provides a foundation for multilingual representation research at a scale that was simply not available in open weights before.
Long-term. This is a replicable testbed for the open research community. That word matters: replicable. When a research group publishes results using a proprietary API, no other group can reproduce those results exactly. The model weights are opaque. The serving infrastructure is unknown. Replication becomes approximation. With Gemma 4, every experiment is reproducible. Every ablation study can be verified. Every claim about model behaviour can be tested against the actual weights.
The early signals are already there. Yale University used Gemma for Cell2Sentence-Scale, a project applying language models to cancer therapy discovery. That kind of application, where the stakes are real and the regulatory environment is exacting, requires the combination of frontier capability and open transparency that Gemma 4 provides. Whether you are studying MoE routing behaviour, efficient inference techniques, or multilingual representation learning, you now have a production-grade model family with no usage restrictions and full architectural transparency.
What it means for founders
Ship AI products without the API bill
Short-term. Stop burning venture capital on per-token API costs. Every OpenAI API call is a line item that scales linearly with user growth. Every Google Cloud AI request is a dependency on a pricing schedule you do not control. Gemma 4 lets you build, test, and deploy AI features on your own hardware from day one. The 26B MoE variant is the sweet spot: near-frontier quality at a fraction of the inference cost of equivalent API-based models. You own the model. You own the data. You own the economics.
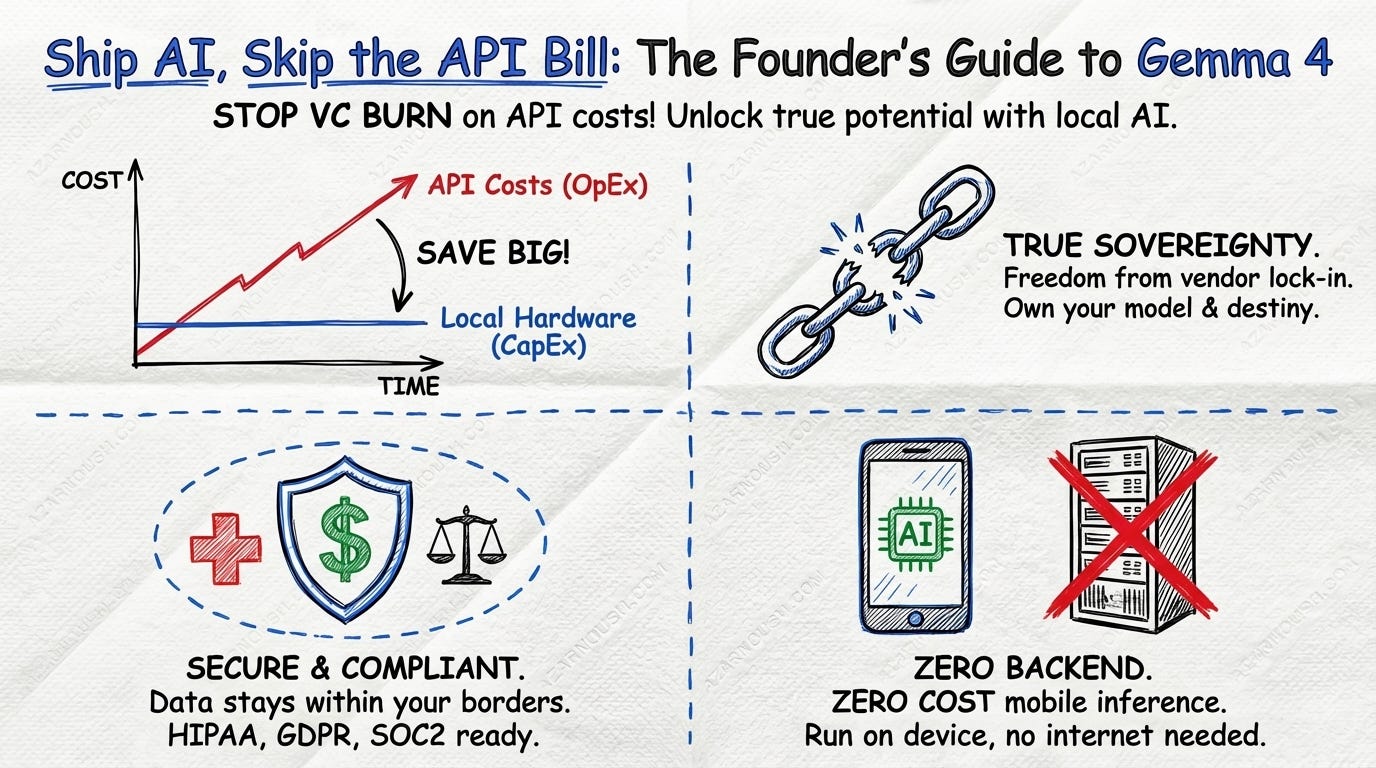
The math is straightforward. If you are building a product that makes thousands of inference calls per user per day, API costs become a material component of your cost of goods sold. With local inference, the cost is the hardware, and hardware is a capital expenditure, not an operational one that compounds with every new user.
Long-term. The real unlock is sovereignty. Not the ideological kind, but the practical kind. You are not dependent on any single cloud provider’s pricing decisions, rate limits, or terms of service changes. OpenAI adjusts its pricing? Irrelevant. Google Cloud changes its API terms? Does not affect you. Your inference infrastructure is yours.
For founders building in regulated spaces, fintech, healthtech, legaltech, edtech, this matters acutely. Data residency requirements are not suggestions. They are legal obligations with real penalties. Model control is not a nice-to-have. It is a prerequisite for shipping products that handle sensitive data. Gemma 4 under Apache 2.0 means you can deploy AI in environments where data must stay within a specific jurisdiction, on specific hardware, under specific controls. Compliance becomes an engineering problem with a known solution, not a legal negotiation with a cloud provider.
The on-device variants add another dimension. If you are building a mobile-first product, the E2B and E4B models mean you can embed AI features directly into your app without a backend inference bill at all. No servers to scale. No cold starts to manage. The model runs on your user’s device, and your cost is zero per inference.
Technical deep dive
The Apache 2.0 shift
Previous Gemma models shipped under a custom licence. It was permissive in spirit, Google was clearly trying to be open, but it contained usage restrictions that created real friction. The Hacker News community, not known for subtlety, called the shift to Apache 2.0 “a big deal”. They were right. Apache 2.0 is not incrementally more open than a custom licence. It is categorically different. It is the most widely adopted open-source licence in the world. Every enterprise legal department has a pre-approved Apache 2.0 policy. Every compliance framework recognises it. The decision to use it signals that Google is not hedging. These weights are open, commercially, fully.
Intelligence per parameter
Gemma 4’s efficiency is not marketing. The 31B dense model scores 1452 on the Arena AI text leaderboard, placing it third among all open models globally. The 26B MoE scores 1441, sixth place, while activating only 3.8 billion parameters at inference. Google’s claim that Gemma 4 “outcompetes models 20x its size” is grounded in these numbers. The MoE architecture uses 128 total experts with 8 active at any given inference step. The router learns which experts to activate based on the input, meaning the model specialises dynamically without paying the cost of running all 128 experts at once.
Benchmark supremacy
The generational leap from Gemma 3 to Gemma 4 is not incremental. It is dramatic. On AIME 2026, a mathematics benchmark, the 31B model scores 89.2% compared to Gemma 3 27B IT’s 20.8%, a fourfold improvement. On LiveCodeBench v6, a coding benchmark, the score jumps from 29.1% to 80.0%, nearly a tripling. On tau-2-bench, which measures agentic tool use, the improvement is from 6.6% to 86.4%, a thirteen-fold increase. On MMMLU, covering multilingual understanding, the score rises from 67.6% to 85.2%.
These are not marginal gains on synthetic benchmarks. AIME measures advanced mathematical reasoning. LiveCodeBench evaluates real-world programming tasks. Tau-2-bench tests whether a model can actually use tools in an agentic workflow. The thirteen-fold improvement on agentic tool use is the number that should make competitors pay attention. It reflects the architectural focus on function calling and structured output baked into Gemma 4’s design.
Per-Layer Embeddings
The E2B and E4B models introduce Per-Layer Embeddings, a technique where a second embedding table feeds a small residual signal into every decoder layer. Standard transformer architectures share a single embedding at the input. Per-Layer Embeddings give each decoder layer its own channel for token-specific information. The result is more useful capacity packed into a smaller footprint. This is how Google achieved meaningful intelligence in a model small enough to run on a phone: not by stripping features out, but by making each parameter work harder.
Agentic-first design
Gemma 4 ships with native function calling, structured JSON output, native system instructions, and a configurable thinking and reasoning mode. These are not post-hoc additions bolted onto a chat model. They are architectural features. Google is positioning Gemma 4 as an agentic foundation model, one designed to plan, act, and iterate rather than simply respond. The configurable reasoning mode is particularly notable. It allows developers to trade inference cost for reasoning depth, running fast and shallow for simple queries and deep and slow for complex tasks. That kind of flexibility is what separates a general-purpose model from one engineered for production agent workflows.
Ecosystem maturity
Over 400 million downloads since the first Gemma generation. More than 100,000 community variants in what Google calls the “Gemmaverse.” These numbers are not vanity metrics. They represent a mature ecosystem where tooling, fine-tuning recipes, deployment patterns, and community knowledge compound with each release. Modular reported 15% higher throughput for Gemma 4 on both NVIDIA and AMD hardware at launch, day-zero optimisation across hardware platforms, not weeks of community effort after release.
The day-one support list reads like a who’s who of the open-source inference stack: Hugging Face transformers, llama.cpp, MLX, Transformers.js, Ollama, vLLM, Unsloth. Every major framework. Every major hardware target. Every major deployment pattern. When Hugging Face says the models are too good out of the box to easily demonstrate fine-tuning improvements, that is not a humblebrag. It is a signal that the quality bar for open models has moved to a place where the default assumption is competence, not compromise.
Gemma 4 is not the first open model to challenge the dominance of proprietary APIs. But it is the first to do so with frontier-class performance, unrestricted licensing, on-device capability, and an ecosystem that was mature before the model was even announced. The question for the industry is no longer whether open models can compete with proprietary ones. It is whether proprietary API providers can justify their pricing and lock-in when an Apache 2.0 model scoring 89.2% on AIME can run on a Raspberry Pi. The infrastructure shift has happened. The next chapter is what gets built on top of it.